6. Die DocBook Toolkette
Um XHTML von DocBook Sourcen aus zu erzeugen, ist folgender Befehl hilfsreich:
bash$ xmlto xhtml foo.xml Convert to XHTML bash$ ls *.html ar01s02.html ar01s03.html ar01s04.html index.html |
In obigem Beispiel wurde ein XML-Docbook Dokument namens foo.xml mit drei Top-Level Sektionen in eine Index Seite und zwei Sektionen unterteilt.
Die Erzeugung einer einzigen umfangreichen Seite erweist sich als ebenso einfach:
bash$ xmlto xhtml-nochunks foo.xml Convert to XHTML bash$ ls *.html foo.html |
Abschliessend noch die Konversion nach Postscript für Druckzwecke:
bash$ xmlto ps foo.xml # Konversion nach Postscript Convert to XSL-FO Making portrait pages on A4 paper (210mmx297mm) Post-process XSL-FO to DVI Post-process DVI to PS bash$ ls *.ps foo.ps |
Um Dokumente nach HTML oder Postscript zu konvertieren, ist ein Programm vonnöten, welches sowohl die DocBook DTD wie auch ein passendes Stylesheet auf das Dokument anwendet. Hier nun eine Schematik wie Open-Source Programme dies in gegenseitiger Kooperation erwirken:
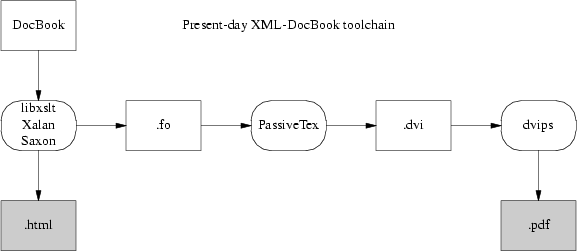
Die Konvertierung des Dokumentes und die Anwendung der Stylesheet Transformation wird durch einer der links ersichtlichen Programme gehandhabt werden. Mit ziemlicher Gewissheit wird dies durch xsltproc bewerkstelligt, dem Parser, der in der Red Hat 7.3 Distribution enthalten ist. Die anderen zwei, Saxon and Xalan, sind Java Programme. Es erweist sich als vergleichsweise einfach qualitativ hochstehendes XHTML aus DocBook zu generieren; die Tatsache, dass XHTML nur eine weitere XML DTD ist, begünstigt diesen Umstand. Konversionen nach HTML werden durch die Anwendung eines überaus einfachen Stylesheets erwirkt und dies ist zugleich alles wissenswerte diesbezüglich. RTF zu kreieren erweist sich als ebenso simpel; von XHTML oder RTF aus, ist es ein Hasensprung zur Generierung eines 'flachen' ASCII Textes.
Als mühsamer Fall erweist sich Druck. Die Generierung qualitativ hochstehender, gedruckter Erzeugnisse (welche praxisbezogen Adobe's PDF (Portable Document Format) involvieren) erweist sich als ungeheur umständlich. Die richtige Umsetzung bedarf der algorithmischen Duplizierung der heiklen Entscheidungen eines menschlichen Schriftsetzers, die bei einer Konversion von Inhalt nach Präsentation vonnöten sind.
Erstlich übersetzt ein Stylesheet die strukturelle Beschreibung von Docbook in einen anderen Dialekt von XML — FO (Formattierungs Objekte). FO Beschreibung lässt sich als Dokumentenbeschreibung klassifizieren; man kann es sich sinnbildlich als eine Art funktionales XML-Äquivalent zu troff vorstellen. Es muss nach Postscript konvertiert werden, damit nachfolgend ein PDF Dokument kreiert werden kann.
Die Toolkette, die in der Red Hat Distribution enthaltene ist, handhabt diese Angelegenheit durch ein TeX Makro Paket namens PassiveTeX . Es übersetzt die Formattierungsobjekte, die durch xsltproc generiert worden sind, in Donald Knuth's TeX Sprache. TeX war eines der ersten Open-Source Projekte; eine alte, jedoch sehr mächtige Dokumentbeschreibungssprache, die von Mathematikern verehrt wird (da sie inbesondere für die Umschreibung von mathematischen Notationen durchdachte Möglichkeiten bietet). TeX hat sich auch für grundlegende schriftsetzende Herausforderungen bewährt. TeX's Ausgabe, welche als DVI (DeVice Independent) Format bezeichnet wird, wird dann schliesslich zu PDF transformiert.
Wenn diese Verkettungskonvertierung von XML nach Tex Makros über DVI zu PDF einen klobigen Eindruck hinterlässt, so wirst du nicht falsch liegen. Es klirrt, keucht und ist warzig. Schriftartenkonvertierungen stellen ein signifikantes Problem dar, da XML, TeX und PDF sehr verschiedene Arten von Implementierungen besitzen; die Handhabung von Internationalisierung und Lokalisierung erweist sich als Alptraum. Dies lässt zu der Annahme verleiten, dass der Code nur hinsichtlich der Basisfunktionalität entworfen wurde.
Als elegante Alternative hierzu, ist FOP erwähnenswert, ein direkter FO-nach-Postscript Konvertierer, der durch das Apache Projekt entwickelt wird. Durch FOP, ist das Internationalisierungsproblem, sofern nicht gelöst, zumindest stark eingeschränkt worden; XML Programme passieren jeglichen Unicode an FOP. Die Schriftartenzuweisung an Hieroglyphen ist auch strikte ein FOP Erschwernis. Das einzige Misstand mit dieser Annäherung ist, dass sie noch nicht gebraucht werden kann (zumindest zurzeit noch nicht). Jetzt, im August 2002, befindet sich FOP noch immer in einem unvollendeten Alphastatus — gebrauchbar, aber mit groben Ecken und fehlender Funktionalität.
Die Schematik der zukünftigen FOP Toolkette schaut wie folgt aus:
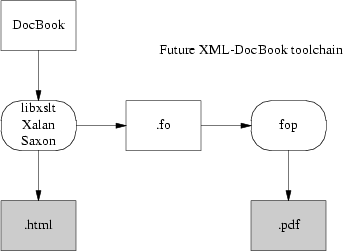
FOP hat einen Mitbewerber zu verzeichnen. Ein anderes Projekt namens xsl-fo-proc wagt den Versuch dasselbige wie in FOP zu realisieren, jedoch in C++ umgesetzt (und deswegen sowohl schneller als Java wie auch keine Java Umgebung erfordernd).